Two datasets are available. Both provide a realistic, camera-captured (no CGI), diverse set of videos. They have been selected to cover a wide range of detection challenges and are representative of typical indoor and outdoor visual data captured today in surveillance, smart environment, and video database scenarios.
- 2012 DATASET was developed as part of the CVPR 2012 Change Detection Workshop challenge (CDW-2012 tab). This dataset consists of 31 camera-captured videos (~70,000 frames) spanning 6 categories selected to include diverse change and motion detection challenges:
- Baseline category represents a mixture of mild challenges typical of the next 4 categories. Some videos have subtle background motion, others have isolated shadows, some have an abandoned object and others have pedestrians that stop for a short while and then move away. These videos are fairly easy, but not trivial, to process, and are provided mainly as reference.
- Dynamic Background category includes scenes with strong (parasitic) background motion: boats on shimmering water, cars passing next to a fountain, or pedestrians, cars and trucks passing in front of a tree shaken by the wind.
- Camera Jitter category contains indoor and outdoor videos captured by unstable (e.g., vibrating) cameras. The jitter magnitude varies from one video to another.
- Intermittent Object Motion category includes videos with scenarios known for causing “ghosting” artifacts in the detected motion, i.e., objects move, then stop for a short while, after which they start moving again. Some videos include still objects that suddenly start moving, e.g., a parked vehicle driving away, and also abandoned objects. This category is intended for testing how various algorithms adapt to background changes.
- Shadows category consists of indoor and outdoor videos exhibiting strong as well as faint shadows. Some shadows are fairly narrow while others occupy most of the scene. Also, some shadows are cast by moving objects while others are cast by trees and buildings.
- Thermal category includes videos that have been captured by far-infrared cameras. These videos contain typical thermal artifacts such as heat stamps (e.g., bright spots left on a seat after a person gets up and leaves), heat reflection on floors and windows, and camouflage effects, when a moving object has the same temperature as the surrounding regions.
- 2014 DATASET was developed as part of the CVPR 2014 Change Detection Workshop challenge (CDW-2014 tab). This dataset includes all the videos from the 2012 dataset plus 22 additional camera-captured videos (~70,000 new frames) spanning 5 new categories that incorporate challenges that were not addressed in the 2012 dataset:
- Challenging Weather category includes outdoor videos captured in challenging winter weather conditions, i.e., snow storm, snow on the ground, fog.
- Low Frame-Rate category contains videos capture at varying frame-rates between 0.17 fps and 1 fps.
- Night category includes videos captured at night (difficult light conditions) of, primarily, motor traffic.
- PTZ category contains video footage captured by pan-tilt-zoom cameras in slow continuous pan mode, intermittent pan mode, 2-position patrol-mode PTZ, or zooming-in/zooming-out
- Air Turbulence category includes outdoor videos showing air turbulence caused by rising heat.
For testing and evaluation, accurate ground truths (see Ground truth below for details) are made publicly available for all the frames of all the videos in all six video categories of the 2012 DATASET.
In addition, whereas ground truths for all frames were made publicly available for the 2012 DATASET for testing and evaluation, in the 2014 DATASET, ground truths of only the first half of every video in the 5 new categories is made publicly available for testing. The evaluation will, however, be across all frames for all the videos (both new and old) as in CDW-2012. This will, we hope, reduce the possibility of overtuning algorithm parameters.
The videos have been obtained with different cameras ranging from low-resolution IP cameras, through mid-resolution camcorders and PTZ cameras, to far- and near-infrared cameras. As a consequence, spatial resolutions of the videos vary from 320x240 to 720x576. Also, due to diverse lighting conditions present and compression parameters used, the level of noise and compression artifacts varies from one video to another. The length of the videos also varies from 1,000 to 8,000 frames and the videos shot by low-end IP cameras suffer from noticeable radial distortion. Different cameras may have different hue bias (due to different white balancing algorithms employed) and some cameras apply automatic exposure adjustment resulting in global brightness fluctuations in time. The frame rate also varies from one video to another, often due to a limited bandwidth.
We believe that the fact that our videos have been captured under a wide range of settings will help prevent this dataset from favoring a certain family of change detection methods over others. These datasets will be revised/expanded from time to time based on feedback from the academia and the industry.
Ground truth
To enable a precise quantitative comparison and ranking of various algorithms, all of our videos come with accurate ground-truth segmentation and annotation of change/motion areas for each video frame. In each frame, “truly changing” regions have been carefully localized with the assistance of human operators. Such regions meet the following constraints:
- they are not part of the background (i.e., trees, waves, flags, etc. are excluded);
- they are people, animals, or man-made objects, e.g., cars, trucks, boats, trains, bags;
- a moving object that suddenly stops, e.g., car/pedestrian at a street light, an abandoned object, etc., should be detected for a short while before being merged into the background.
- light reflection, air turbulence caused by heat, and spotlight halos are not considered as moving objects, even when generated by moving objects.

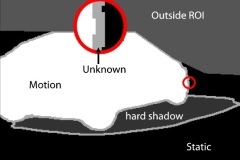

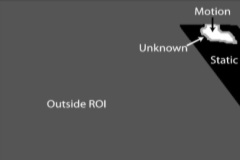
Two video frame samples with associated manually-labeled ground truth.
Additionally, hard shadows have been manually labeled in order to enable comparison of algorithms based on their robustness to shadows. The figure above shows a sample annotated frame from our dataset with all ground-truth labels that can be assigned. Please note the level of detail in the labeling and the accuracy of the object boundaries.